基于 MySQL 的热数据与冷数据分离设计与实现
作为一家提供商业气象数据服务的创业公司,我们一直都有一项「欠交的作业」没有完成,那就是合理的数据规划和数据治理规范。对于早期的初创公司而言,可能很难从一开始就能构想到需要对数据存储进行合理的规划并制定长期规范,大多都是简单使用单实例的数据库,直到随着业务增长数据量累积到一个不得不严肃考虑这个问题的地步。
数据库发展简介
数据量的增长其实一直是随着互联网的发展呈现爆发式增长的,因为各种各样的数据都在不断的被原样或者是经过少量的更改和增补后拷贝到互联网的各个角落。为了适应互联网数据的海量增长,在后端和架构意义上而言,数据库的发展也大致经历了「单库单表 -> 主从读写分离 -> 分表分库 -> NoSQL -> NewSQL」这样的过程。
一开始,我们把数据都堆在一个数据表里;后来为了提高性能、增加数据扩展的能力,采用了「主从读写分离」和「分表分库」的方式,前者只需要在主从实例之间做数据同步而不会对既有业务有较大的影响,后者则需要用一套切合业务逻辑的方式合理的制定分表分库的策略;再后来出现的 NoSQL,打破了传统关系型数据库固有的一些限制,它们有不同的类型,有的是为了解决高性能读写的需求,有的则是为了解决海量数据存储的需求,还有的需要数据结构本身具备可扩展性;NoSQL 的不同类型在不同的侧重点解决了不同的问题,而如今出现的 NewSQL 则倾向于把数据库看作是一个黑匣子服务,你还是可以遵照传统的数据库协议的使用方式(比如传统 MySQL 的使用方式)来使用它,但数据存储服务本身既可以同时具备较高的读写性能又可以轻易的实现横向扩展。NewSQL 并不是一个全新的东西,我们可以把它看作是之前积累的数据库技术结合分布式技术的集大成解决方案,它使得使用数据服务的人几乎不需要再考虑性能和扩展问题,而尽量在数据服务内部实现高可用、高性能、可扩展。
「热数据」和「冷数据」
在简单了解了数据库发展历程之后,再介绍一下我们目前在数据存储上遇到的问题和一些业务背景。
作为气象大数据服务商,随着我们积累的数据量和数据种类越来越多,我们发现我们已经迫切需要一个在全局层面统一的数据路径规划和规范。很多时候,我们从数据源获取到的数据,既需要马上分发给线上用户,也需要被内部项目使用,如果只是简单的按需实现,那数据流转会非常混乱。基于这种考虑,我们引入了「热数据」(「在线数据」)和「冷数据」(「离线数据」)的概念:
「热数据」指的是需要即时对用户进行分发的数据,即从数据源抓取之后经过数据清洗,需要即时存储到可以快速分发的存储介质(如 Redis)供 API 或直接面向用户的系统使用。「热数据」线需要重点保障服务质量和稳定性,为了保证数据的时效性,在数据处理上也是优先级高的数据。「热数据」可能是临时或短期存储的,后来的数据可能会覆盖已有的数据。
「冷数据」指的是不需要即时分发给用户的数据,这些数据甚至可能永远都不会原样分发给用户的,但它们需要经过长期的积累,使我们可以从中得出基于此的更高 level 的分析。「冷数据」典型的使用场景是供内部数据评估系统做数据准确度的评估分析,同时也可以给算法团队建模使用。设立这个数据线的原则是不影响「热数据」的服务质量,尤其是时效性和稳定性,同时也满足一些非线上项目的数据使用需求。
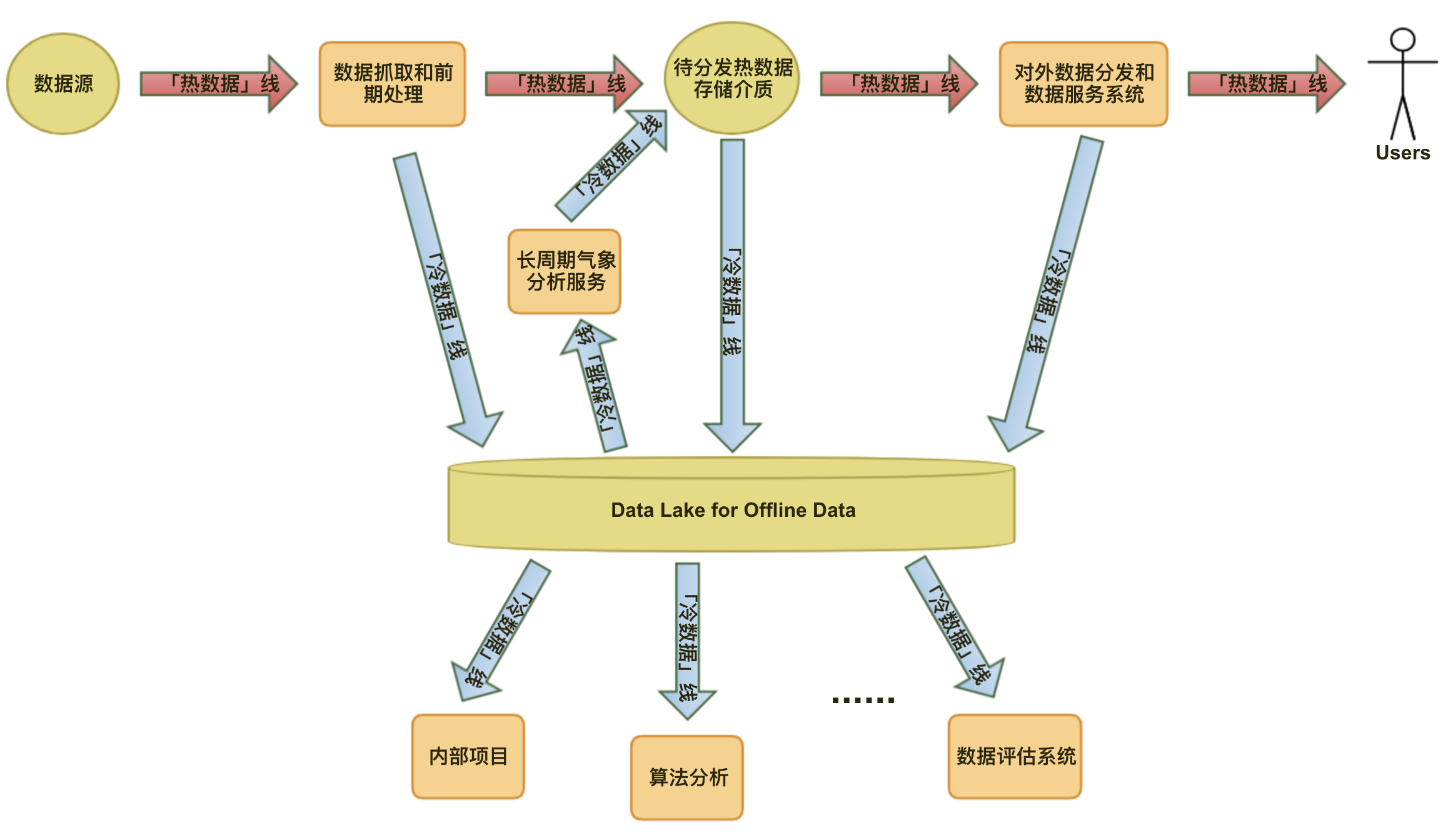
这其实也不是什么新鲜的概念,很多做数据服务的公司都有类似的设计,我们只是根据我们的业务特点借用了这样的概念,不过它们的含义可能与你在其他地方看到的类似概念的含义有所不同。
结合我们具体的业务场景来说,「热数据」线其实已经一直在有效运转了,即我们从数据源获取到数据然后尽快存储到高性能存储介质中,再通过 HTTP 协议分发出去,这些数据都是即时更新的最新的数据。而其中有一些类型的数据,我们还需要在可视化项目中查看历史变化情况,并能进行简单的聚合和计算,这意味着数据需要积累一段时间,那我们也需要一些可以持久化存储的介质。
拿天气实况来举例,我们在采集完数据之后,随即就存储最新的一份数据到 Redis,而出于数据积累的角度考虑,我们同时也把新数据写入 MySQL。这是之前我们的做法,然而随着数据量的极速扩大,问题很快就会出在 MySQL 上。对于「亿」级别行数往上的 MySQL 单表,操作会变得越来越困难,而大范围的抽数或者插入数据的操作都可能使得整个 MySQL 无法提供服务,这对于线上业务而言是不可接受的。
离线数据中心的实现
在提出了「冷数据」的概念之后,我们意识到那些久远的历史数据其实需要存放到「冷数据」的数据中心池子里,而线上 MySQL 只需要保留最近一段时间的数据即可。另外,为了不改变现有项目使用数据的方式,降低数据库使用者的门槛,不管是对于线上数据库还是「离线数据」的数据中心,我们都需要兼容 MySQL 单表的使用协议。
很快我们就开始考虑 NewSQL 的方案,TiDB 很自然地进入了我们的视野,这是一个既可以兼容现有数据使用方式,又可以实现数据横向扩展的完美方案,但无奈搭建一个最小版本的 TiDB 数据集群的成本,相比于目前我们把它作为一个「离线数据」存储中心的角色而言,还是有一些偏高,而我们的存量服务也基本都是基于阿里云的,所以最终我们选择了阿里云推出不久的云数据库 PolarDB。其间我们还研究了很多其他数据库方案,比如 DRDS、OceanBase、Google Cloud Spanner、Amazon Aurora 等。
数据同步和数据过期
有了离线数据存储中心之后,我们开始考虑如何把「热数据」转化为「冷数据」,同时也使得线上数据库可以自动过期超出时间窗口的历史数据。另外,由于内部可视化项目也希望看到实时的实况数据,所以离线数据最好也能很快获得最新的实况数据。
既然是两个 MySQL(集群)之间的实时数据转移,很自然的就想到了我们可以做类似主从节点之间通过 binlog 的数据同步机制,这个同步可以做到秒级延迟,在实时性上是完全可以接受的。不过这不能是简单的数据同步,因为离线数据是不能同步线上数据的过期操作的。更具体的,我们可以概括成:MySQL 从节点同步主节点所有数据增添和数据修改的操作,而对于数据的删除操作不做同步。
在调研之后,我们发现 TiDB 提供的同步工具 Syncer 可以实现这一点,我们只需要在配置注明过滤掉 DELETE 的 DML 语句即可,示例如下:
1 | [[skip-dmls]] |
而数据过期方案则可以直接借助 MySQL 本身的 EVENT 和 PROCEDURE 机制完成。首先我们可以创建一个删除数据的 PROCEDURE:
1 | CREATE DEFINER=`weather`@`%` PROCEDURE `weather_data`.`del_old_data`(IN `date_inter` int) |
这个 PROCEDURE 功能是删除 weather_now_history 表中 date_inter 天之前的数据。然后我们再创建一个 EVENT:
1 | CREATE EVENT del_old_data |
这个 EVENT 则会每天调用一次名为 del_old_data 的 PROCEDURE,并同时把 date_inter 赋值为 30。这意味数据库每天会删一次数据,使得线上数据库一直只保留最近 30 天的数据,而全量的数据是在数据写入时就实时同步到了离线数据中心,可谓完美。
持续改进
All problems in computer science can be solved by another level of indirection.
—— David Wheeler
上述的具体业务场景更多的还是 case by case 的解决了「热数据」和「冷数据」的分离和转化问题,这意味着方案并不具有普适性,以后我们遇到其他的数据库或者不同的数据使用场景可能就不再适用。另外,很多时候,「热数据」和「冷数据」的划分并不是那么明晰的,对于「冷数据」的需求有可能转变为「热数据」需求,我们需要可以灵活切换的机制,做到数据源只抓取一次(「热数据」和「冷数据」不要分别抓取),而抓取到的数据可以任意自由的流淌到「热数据」或「冷数据」线使用,这意味着我们在数据抓取和数据存储之间应该再做一层隔离。
要实现数据抓取和数据存储之间的隔离,我们可以采用「发布/订阅模式」:简单说,数据抓取服务在获取数据之后将数据发布到消息队列,后面的存储服务任意订阅这个消息队列再做存储,这样数据源只需要抓取一次,我们可以把它作为热数据使用,也可以作为冷数据使用,甚至可以即作为热数据又作为冷数据使用,切换起来也十分简单。这是后续系统架构可以改进的一个地方。
另外,离线数据中心仅仅使用 PolarDB 对于我们可能产生的数据量级而言也是远远不够的,我们还需要更低成本的数据存储方案来存储时间更久远、平时几乎不大会访问的一些需要被「归档」的数据,这个时候,一些基于列存储的 NoSQL 数据库可能可以派上用场。
数据治理需要一个长期持续的过程,我们还在结合自身的业务场景不断的摸索当中。