完全理解并发
越是往后端深入到 Web 开发和分布式系统,就越会觉得把「并发」理解清楚是多么重要,而每天的日常工作中很多时候都需要处理与并发有关的话题,大到整个系统架构层面的并发考量,小到某一段代码的并发控制。
本来不想把这篇文章加入到「完全理解」系列,因为觉得「并发」涉及到的东西实在是很多,而我想凭借一篇博客企图「完全理解」那是不现实的。但虽然不能做到「完全理解」,但我还是会尝试尽力提纲挈领的把「并发」相关的话题都理清楚,把脉络勾勒出来,让它尽可能对得起「完全」吧。毕竟,如果以后我有了一些更深的理解,我还可以继续迭代这篇文章。
并发与并行
在开始正式的话题之前,我们先来厘清两个概念——「并发」与「并行」。
Erlang 之父 Joe Armstrong 曾经用一张非常简单易懂的图解释了「并发」与「并行」的区别:
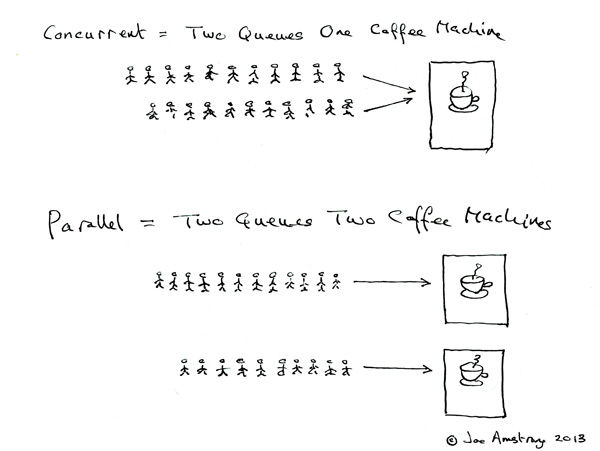
「并发」是同学们排成两队,然而却只有一个咖啡机在工作,所以两个队列排在前面的同学交替使用咖啡机;「并行」则是两台咖啡机分别服务两个独立的同学队列,它们同时进行,互不干扰。
这样的例子简单易懂,但依然还需要更进一步说明的是,「并发」与「并行」其实并不是同一个维度上非黑即白的两个对立的概念。「并发」更多的强调的是有没有这样的能力或特征,它是从事物的性质和对外表现上来说的,它不在乎你内部是如何实现「并发」的,相对而言是在更高层次上的概括,而「并行」则规定了它们在物理上一定是同时进行的,相对而言更严格。
具体从编程的角度来说,「并行」甚至可以是实现「并发」的一种手段,比如用下文所要讲的「多线程」或「多进程」的方式来赋能某一段程序的「并发」能力:为了使程序具备「并发」的能力,采用「多线程」或「多进程」在应用层面上可以「并行」运行的具体实现手段来为其赋能。
计算机操作系统发展史
要追根溯源的来理解「并发」,我们首先应该了解一下计算机操作系统的发展历史。因为回顾整个计算机操作系统的发展历史,我们就会发现,几乎所有的关键历史节点,都是因为它使得计算机系统拥有了更强的并发处理能力而变得重要的。
在计算机诞生之初,是没有操作系统这种东西存在的,当时人们只能先把打孔纸带通过输入机将程序传入计算机,再启动运行。在程序执行完毕之后,打印机把计算结果输出,在现场监督程序执行的程序员再取走纸带。在这个时期,同一个计算机系统在同一时间只能处理唯一确定的一件事情。
后来人们发明了批处理系统。批处理系统相当于计算机上的一个任务监督程序,在它的控制和调度下,计算机能够自动的、成批的处理一个或多个用户的任务。在批处理系统的帮助下,各个任务之间可以自动衔接,减少了需要人工建立任务和手工操作的时间,提高了计算机的利用效率。
再后来,随着 CPU 性能的不断提升,出现了分时系统和实时系统。分时系统是把 CPU 的运行时间分成很短的时间片,按时间片轮流把 CPU 分配给各联机任务使用。若某个任务在分配给它的时间片内不能完成其计算,则该任务暂时中断,把 CPU 让给另一任务使用,等待下一轮调度时再继续其运行。由于计算机速度很快,各个任务之间轮转得也很快,给每个用户的感觉是他独占了一台计算机。而每个用户可以通过自己的终端向系统发出各种操作控制命令,在充分的人机交互情况下,完成作业的运行。为了解决分时系统不能及时响应用户指令的情况,又出现了能够在严格的时间范围内完成事件处理、及时响应随机外部事件的实时系统。
IBM 于 1964 年伴随着大型机 System/360 推出了通用操作系统 OS/360,这个通用的操作系统使得不同型号的计算机设备也可以在同样的操作系统控制下使用同样的外部设备(如打印机)和更上层的软件,并且这些设备之间可以相互连接,共同工作。通用操作系统使得不同型号的计算机设备之间能够真正组成网络来处理复杂的任务。软件工程领域的著作《人月神话》也是诞生于 IBM 的这个项目。
再往后就是我们相对更加熟悉的 Unix/Linux/Windows/OS X 这些现代操作系统诞生、迭代、版本更替的历史,目前这些操作系统的并发能力已经远远超出了当时的 OS/360,而现代计算机网络的加持更是使得理论上的计算机并发处理能力几乎已经没有了上限。
从整个计算机操作系统的历史我们可以清晰的看到历史上的计算机科学家们是如何一步一步来提升计算机处理任务的效率的。从一开始需要手工的开启、监督、结束单一任务,到使用批处理系统来自动化的监督任务流水线,再到使用分时系统来让 CPU 在多个任务之间不停的轮转,然后用后文要详述的多 CPU 使用多进程和多线程的方式来进一步提升多任务的执行效率,最后我们使用通用计算机系统来组成庞大的计算集群来处理复杂的各种各样需要随机响应的任务,并发能力一次比一次有了质的提升。
如果说「摩尔定律」使得 CPU 的性能可以指数级的增长来从单机速度上提升任务完成的效率,那么不断的提升并发能力则是更高屋建瓴的考虑如何不间断不浪费的来「压榨」CPU 的高性能,这种思考问题的维度比一门心思的考虑提升单 CPU 的速度更具有现实意义,对于解决现有问题来说是更加高明的选择。尤其是在「摩尔定律」行将失效的今天,采用分布式的方式提高整个系统的并发处理能力几乎成了唯一的选择。
多进程与多线程
让我们先回到单机时代,来了解目前主流的并发模型——多进程与多线程。现代操作系统早已进入多 CPU 时代,自然会支持多进程和多线程。「进程」就是操作系统中一个具有独立功能的程序,操作系统管理所有进程的执行并且以进程为单位分配存储空间。一个进程还可以拥有多个并发的执行流程,这些并发的执行流程是可以获得 CPU 调度和分派的基本执行单元,也就是线程。
进程是计算机资源的拥有者,创建、切换和销毁都有较大的时空开销,而一个进程内的所有线程共享这个进程的资源,更轻量级,对其的相关操作也开销更小。需要注意的是,对于单核 CPU 系统而言,并行其实是不存在的,任何时刻 CPU 其实只能被一个线程所获取,线程之间共享了 CPU 的执行时间。由于切换的速度很快,对外表现为并发执行的样子。
多进程和多线程是如今高级编程语言中实现并发的常规模型,比如 C++、Java、Python。同时为了解决程序中多个进程和线程对资源的抢占问题,还引入了「锁」的概念。在这个并发模型中,需要开发人员利用「锁」来处理资源抢占的问题,也就是不让某一个资源同时被多于一个进程(线程)所处理而带来不可预期的后果。
既然有多进程和多线程,那么「锁」自然也有「进程锁」和「线程锁」。我们知道两个进程其实是相互独立的,各自拥有操作系统分配的独立资源,而「进程锁」是为了防止两个进程对他们所占用的资源以外的共享资源同时访问,一般可以使用操作系统级别的信号量来实现。相对应的,「线程锁」则是保证同一段代码在同一时间只有一个线程在执行,一般各语言本身或类库会提供实现方式。
分布式并发锁
「分布式锁」跟「进程锁」和「线程锁」很像,不过它更多的是使用在计算集群的场景中。在本质上,进程锁、线程锁和分布式锁的作用都是一样的,只是作用的颗粒度不一样。线程锁作用于单一进程的范围,进程锁作用于单一操作系统的范围,而分布式锁则可以作用于网络结构中。在分布式集群当中,我们使用分布式锁来保证不同线程对代码和资源是独占的。
如何实现一个完美的分布式锁呢?我们先来分析一下实现一个好的分布式锁应该满足什么需求:首先这个加锁操作应该是原子性的,否则这个锁是有可能被「击穿」的;其次锁一般还需要有过期时间,使得某一次执行异常没有移除锁的情况下也能自然过期然后重试。
以大多数人都熟悉的 Redis 为例,我们可以使用 Redis 的 set 指令,把 key 作为锁的标志。尤其注意的是,这个操作原子性包含了查看锁存不存在、加锁和设置过期时间三步操作,它们合在一起应该具有原子性(至少前两步)。也就是说,如果我们需要先使用 get 指令查看锁存不存在再决定是否加锁,这个锁已经不是一把好「锁」了。好在 Redis 2.6.12 以上的 set 指令 支持了同时加参数设置过期时间和判断 key 是否存在,比如使用 SET lock_key lock EX 5000 NX,NX 保证了锁不存在时才上锁,而 Redis 指令本身具有原子性,这样就实现了一把看起来还不错的锁。在任务执行完毕后我们还需要用 del 指令主动把锁删掉以释放资源。
上述例子只是一个简单的场景,这个锁其实还并不是完美的。思考这样的问题:如果某一次操作线程 A 执行的特别慢,超过了过期时间,这个时候锁已经自动过期失效了,这样就有可能两个线程同时在执行了。如何避免这样的问题这里不再详述,感兴趣的同学可以参考末尾 References 里面的内容。总之,实现一把完美的分布式锁可能并没有想象中那么简单。
异步
对于高级编程语言而言,多进程和多线程的并发模型更多的还是与操作系统底层对于并发的实现是保持一致的。也就是说,在它们的抽象层级上,实现并发的方式基本只是复刻了操作系统底层的并发模型。而 JavaScript 却不一样。
JavaScript 在诞生时就被定位为在网页前端执行的脚本,为了保证线程安全,而且主线程也不会被 I/O 等待所阻塞而失去响应,JavaScript 在设计阶段就采用了「异步事件模型」。这个模型并不是 JavaScript 独有的,它只是借用了这个古老的模型来解决它自身的问题。
在实际情况中,异步事件模型也是采用多线程的方式来实施的。但是对于开发人员而言,你永远只需要跟主线程打交道,而所有的这些交互都是所谓「异步」的,也就是说,你调用的任何一个 API 都在执行成功后主动告知你执行结果,这样你就可以不必被任何 I/O 所堵塞(详细的关于异步、同步、阻塞和非阻塞的辨析可以看这里:《完全理解同步/异步与阻塞/非阻塞》)。既然不会被阻塞,那么你可以以很快的速度调用很多个你需要调用的 I/O,这些 API 在自己执行完毕后会主动返回结果,你可以拿着结果来继续做后续的事情,而其他时刻你完全是「自由」的。
在这个并发模型中,你不再需要处理各种「锁」的问题,因为真正和你交互的只有主线程。可是作为开发者,你可能需要考虑如何处理代码中的各种异步流程。因为在异步的世界里,代码不再是简单的按照书写顺序来顺序执行的,如何在工程中清晰合理的组织这些流程是在这个并发模型下需要考虑的问题。
各种各样的并发模型
这个世界上除了多进程/多线程的并发模型和异步事件并发模型,还有很多其他的并发模型,比如 Erlang 的 Actor 并发模型和 Golang 的 CSP 并发模型。在 Erlang 的并发世界里,有很多比内核线程还要轻量级的对象,它们之间通过各种 Message 来进行数据共享。这些对象非常轻,可以同时成千上万的被创建出来实现并发,而对象之间都通过发消息来进行数据交换,根本不需要「锁」。
在一个没有「锁」的世界里,并发的效率是可以大大的提升的。
总结
每一个并发模型都有其存在的意义和价值,不过在具体的业务场景下,采用不同的并发模型的好坏却是客观的。
真理是存在的,可以被不断逼近却永远无法被任何事物所完美诠释。在技术的领域里,没有永恒的真理,但是真理永远值得被追求。