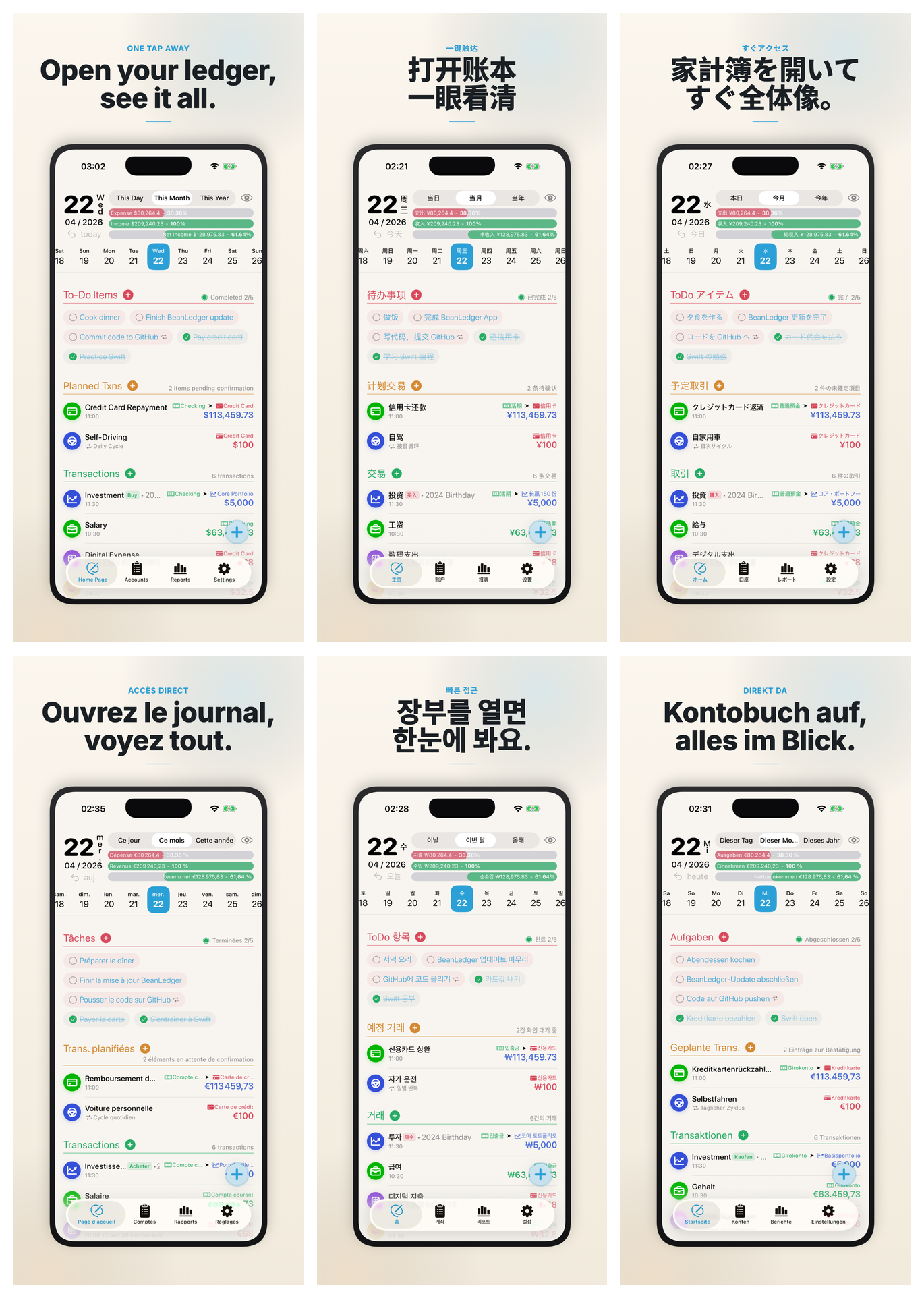
用 AI 搞定 17 种语言:BeanLedger 的多语言开发实践
BeanLedger 目前支持 17 种语言。半年前如果有人跟我说,一个独立开发者能把一个 App 做到 17 种语言上架全球市场——每种语言都有本地化的营销截图、App Store 文案和应用内翻译——我大概率会觉得他在吹牛。
但事实就是,我做到了。靠的是 AI。
为什么要做这么多语言
道理很朴素:App Store 是一个全球市场,绝大多数用户只会用母语搜索和下载 App。一个只有英文和中文的记账应用,在日本、韩国、巴西、土耳其的用户眼里基本等于不存在。多语言不是锦上添花,而是触达用户的基本功。
但传统的多语言开发是什么体验?找翻译公司报价、逐条对照翻译、来回校对、等待交付——光想想这个流程就头大,成本和周期足以劝退大部分独立开发者。更别提每次发版更新文案和截图时,这套流程还得再走一遍。
过去的多语言开发,本质上是只有大公司才玩得起的游戏。 AI 彻底改变了这个局面。
而且效果是立竿见影的。BeanLedger 上线多语言支持不到一周,我就收到了一封来自法国用户的邮件——用法语写的,详细询问了几个功能细节。能看出来他是先在法语版的 App Store 页面了解到这个 App,下载试用之后才写信过来。我法语一个字不会,但靠着 AI 翻译,跟他用法语来回沟通了好几轮,完全没有障碍。最终这位用户购买了 BeanLedger Pro 永久会员。一个人在法国,因为你的 App 有法语支持而成为了付费用户,而你靠 AI 用法语完成了整个售前沟通——这件事在过去对独立开发者来说几乎不可想象。
应用内翻译:xcstrings + AI 批量翻译
BeanLedger 使用 Xcode 原生的 .xcstrings(String Catalog)来管理所有本地化字符串。整个应用有三个 xcstrings 文件:Localizable.xcstrings 负责主界面文案,InfoPlist.xcstrings 负责系统权限描述等系统级文本,AppShortcuts.xcstrings 负责 Siri 和快捷指令的语音短语——三个文件加起来,覆盖了用户在 App 内、系统层和语音交互中能看到的所有文字。
新增一个 feature 写完英文原文后,翻译流程其实很直接:告诉 AI「翻译这些新增的 key」,它自动识别所有待翻译条目,一口气输出 16 种目标语言的翻译。翻译前会先扫描已有翻译里的术语——比如「Transaction」在日语里一直译为「取引」,韩语里一直是「거래」——然后严格复用,不会突然换个说法。翻出来的结果里,占位符(%@、%lld)、Markdown 格式、品牌名「BeanLedger」都原封不动待在正确位置,CJK 语言也会自动用全角标点。
听上去好像没什么难的?但真正让这套流程稳定跑起来的,是我踩了无数坑之后攒出来的一套规则。
术语一致性是翻译质量的生命线
这是我吃过最大的亏:术语一致性比单条翻译的优雅程度重要十倍。
早期没特别注意这一点,AI 每次翻译时可能对同一个概念用不同的词——「Account」这条译成「账户」,那条又变成了「帐户」。中文语境里你可能觉得差别不大,但放到德语、波兰语这种有复杂词形变化的语言里,术语不统一直接影响用户理解。
后来我在项目的 AI 指令文件里加了一条硬规则:翻译任何新 key 之前,必须先扫描同语言已有翻译,提取术语表,严格复用。 发现已有翻译本身不一致?那就在同一次修改中统一修正,绝不允许引入第三种说法。
这条规则落地之后,翻译质量有了质的飞跃。
大批量翻译必须分批
另一个血泪教训:长翻译列表绝对不能一口气翻完。
这听起来像是一条「AI 使用技巧」,但它直接关系到翻译工作的成败。200 个 key 翻 16 种语言,让 AI 一次性全部输出,它几乎一定会中途截断或者后半段质量下滑。结果是你既不知道翻到哪了,也不确定已翻的部分质量是否稳定——全部推倒重来比挨个检查还快。
我现在的做法是强制分批:默认每批 20-30 个 key,长文本或需要处理复数变体(比如波兰语有 one/few/many/other 四种复数形式)时再减半。每批翻完报告进度,下一批从断点继续。术语表在第一批之前就锁定,贯穿全程。
这个规则我直接写进了项目的 AI 指令文件,标注为「硬性规则,不是建议」。凡是没遵守的翻译任务,最后几乎都返工了。
新增一种语言要多久?
当 BeanLedger 从只有中英文扩展到 17 种语言时,每新增一门语言的流程是:先让 AI 产出这门语言的术语表(Glossary),把「Transaction」「Account」「Category」「Budget」这些核心概念的译法钉死;术语表确认后,再按批次翻译所有 key——翻译时要求 AI 写地道的本地表达,而不是从英文逐字硬译,这对用户体验影响巨大。
整个流程下来,新增一种语言大概不到半小时。搁过去,这至少是几周的工作量。
App Store 文案:一份配置文件管 17 种语言
应用内翻译搞定了 App 内部的事,但上架 App Store 还有另一大块:每种语言的商店页面文案和截图。
BeanLedger 用一个 store.config.json 作为所有 App Store 元数据的 Single Source of Truth。这个方案基于 Expo 的 EAS CLI 工具链——虽然 BeanLedger 是纯原生 Swift 项目,但 EAS 的 eas metadata 命令提供了一套还不错的 App Store Connect 元数据管理规范:标题、副标题、关键词、描述、促销文案、更新日志,以及每种设备尺寸的截图路径——17 种语言,全部集中在这一个 JSON 文件里,纳入 Git 版本控制。
围绕这个配置文件有三条命令:
npm run metadata:pull:从 App Store Connect 拉取线上数据到本地npm run metadata:lint:校验字数限制、必填字段等规则npm run metadata:push:一键推送到 App Store Connect 草稿
每次发版的流程就是:让 AI 根据本次改动写好 17 种语言的更新日志,填入配置文件,lint 一遍,push。过去需要一两天的多语言文案更新,现在半小时。
有一点让我觉得很有意思:不同语言的 App Store 描述其实不该是简单互译。日语天然比英语更含蓄礼貌,巴西葡萄牙语更热情奔放,德语则偏严谨正式。AI 翻译时能自然地适配每种语言的表达调性——换成传统外包,你得给每种语言的翻译者单独写 brief 说明语气要求,光这个沟通成本就够喝一壶的。
营销截图:Next.js 渲染 + 自动化导出
App Store 截图是多语言开发里最让人头大的部分——17 种语言 × 2 种设备尺寸(iPhone + iPad)× 10 张截图 = 340 张图。手动做的话,光截图加标注就够忙一个星期。
BeanLedger 的做法是在项目里内嵌了一个 Next.js 应用作为截图生成器。整套流程——从模拟器上截取原始界面图,到渲染出带营销文案和设备边框的最终 App Store 截图——全部由 AI 编写的自动化脚本完成,我自己没手写过一行截图相关的代码。具体来说:先在模拟器上按预定义的截图清单(capture-manifest.yaml)自动截取各语言的原始界面截图;然后 Next.js 读取这些原始截图,渲染成带本地化营销文案和设备边框的完整 App Store 截图;最后通过 Playwright 自动导出 PNG 到指定目录,按语言和设备尺寸归类。
从截图到导出,就这几条命令:
1 | pnpm screenshot:batch # 批量截取原始截图 |
这套流程最大的好处是可重复:每次发版重新截一遍图就行,营销文案改配置文件,不用重新设计任何东西。而且所有语言的布局风格完全一致——不会出现日语截图跟英语截图「画风不统一」的尴尬。
让 AI 记住你的规则
上面这些流程看起来环环相扣,但它们能跑通有一个前提:AI 得知道你的规则。
BeanLedger 项目里有一整套写给 AI 的指令文件(.instructions.md),翻译规范、品牌准则、术语表、CJK 标点规则、代码文件卫生规范……都写在里面。这些文件不是摆设——它们是 AI 每次翻译时保持一致性的关键。
比如:BeanLedger 这个名字在任何语言中都不翻译不音译,中日韩文本里品牌名两侧必须加空格(升级至 BeanLedger Pro);CJK 语言必须用全角标点;分批翻译的默认批次大小、接续方式、术语锁定时机全部白纸黑字写死。
这些指令文件本质上就是给 AI 写的「员工手册」。新来的翻译也得先读完公司翻译规范才能干活,AI 也一样。区别是——AI 每次真的会完整读完这些规范,然后严格执行。它不会偷懒,不会「差不多得了」。 光这一点,比人靠谱多了。
开源出来了
在 BeanLedger 的开发过程中,我把上面这些多语言翻译、App Store 元数据管理、营销截图生成的 AI 工作流抽象成了一套可复用的 SKILL(可以理解为给 AI Agent 安装的领域技能包),开源在 GitHub 上:Maples7/Apple-Dev-AI-Skills。
里面目前有几个核心 Skill:
translate-xcstrings:批量翻译 xcstrings 文件,内置术语一致性检查、分批策略和 CJK 标点规范。eas-app-store-metadata:管理store.config.json,对接 App Store Connect 元数据的拉取、校验和推送。app-store-preview-pipeline:端到端的 App Store 截图生成流水线。
这些 Skill 不绑定 BeanLedger——任何用 xcstrings 做本地化、需要管理多语言 App Store 文案和截图的 Apple 平台项目都能直接用。如果你也在做多语言的 iOS/macOS 应用,拿去,不谢。当然也欢迎 PR 和改进建议。
一个人 = 一个多语言团队
算一笔账:17 种语言的应用内翻译和 App Store 文案,340 多张营销截图,每次发版更新全部语言大概半天时间——以上所有,1 个人 + AI。
搁过去,这个规模至少需要一个专职本地化团队——项目经理、若干翻译、设计师、QA。现在一个独立开发者加上对的工具链,就能做到同样甚至更好的效果。
说到底,人负责定规则和做质量判断,AI 负责大规模执行。你得懂翻译质量好不好、术语用得对不对、文案风格适不适合目标市场——但你不需要自己会说 17 种语言。我之前那篇文章里说的「Know-What 和 Know-Why 的价值正被无限放大」,在多语言开发这个场景下体现得尤其明显。
几条实战经验
写到这里,总结几条踩坑之后留下来的经验:
术语表先行。 不管你用什么工具翻译,每种语言开始之前先把核心术语的译法钉死,然后贯穿到底。这是翻译质量的地基,地基歪了上面全白搭。
规则写成文件,不要记在脑子里。 写成 AI 能自动加载的指令文件,规则越明确,AI 的产出越稳定。你换一台电脑、换一个 AI 模型,规则依然在。
App Store 元数据必须纳入版本控制。 在 App Store Connect 网页上手动编辑 17 种语言,迟早会出错。用配置文件 + CLI,拉取、校验、推送,一切可追溯。
截图生成一定要程序化。 语言超过 3 种手动做就不现实了。前期投入时间搭自动化流程,后续每次发版你都会感谢当初的自己。
分批、分批、分批。 说三遍。大批量翻译宁可多跑几轮,也别试图一把梭然后返工。
这套流程还在持续迭代,远谈不上完美,但已经足以让一个人撑起一个全球化的 App。如果你也是独立开发者,正在犹豫要不要做多语言——别犹豫了,现在就开始。AI 已经把这件事的门槛降到了前所未有的水平。